
그냥 내가 나중에 다시 보려고 책의 예제를 보며 내 방식대로 직접 작성한 코드들이나 책의 짧은 문구들 정리.
남들도 알아볼 정도로 적기는 했는데 책에 있는 내용을 다 담지는 않았음.
좋은 책이니까 궁금하면 사서 읽으셈.
책에서는 php, java 예제가 많았는데 난 이제 코틀린 신도라서 코틀린으로 작성함.
1. Clock Test
책에서는 Clock 같이 시스템 경계를 넘어서는 객체를 사용할 때는 추상화를 권장하고 있다.
이유는 역시나 테스트 용이성 때문.
나의 경우 Clock을 Bean에 등록해서 주입하고 테스트 시에는 Mockito로 Clock을 모킹하는 방법을 사용하고 있었는데 책에서는 Mockito 같은 Mock framework를 권장하지 않기 때문에 이런 방법을 사용하는 듯.
사실 Mock Framework에 대한 혐오는 이미 여러 책에서 귀에 딱지가 앉도록 들어왔기 때문에 앞으로 나도 이런 방식을 채용하게 될듯함.

2. Repository Test
책에서 직접적으로 JPA Repository에 대해 언급하지는 않았지만, 책에서 보여준 예시로 봤을 때 JPA Repository도 결국 외부 Framework를 직접적으로 갖다 사용하는 것이기 때문에 이런 식으로 추상화하는 것이 올바른 사용 사례일듯 하다.
테스트의 경우 Mock Framework를 사용하지 않고 UserRepository를 상속한 FakeUserRepoitory를 사용함으로써 해결 가능.

3. Immutable Object
클래스 생성 시 생성자 혹은 Named Constructor(명명 생성자)에서 제약 조건이 필요한 경우가 있다.
가령 Product라는 객체를 생성할 때 기본적으로 "quantity가 0보다 크거나 같아야 한다"라는 제약 조건이 있을 수 있을 것이다.

Mutable Object의 경우 생성 이후 내부 값을 변경할 때마다 상태 변경 시 이런 도메인 제약 조건을 위반하지 않는지에 대한 테스트를 반복적으로 수행해야 한다.

반면 Immutable Object의 경우 상태를 변경하는 것이 아니라 새로운 객체를 반환하기 때문에 생성자 하나로 도메인 예외 처리가 가능해진다.
근데 우리 사실 모두 JPA 사용하잖아요.
JPA Entity를 불변으로 사용하면 JPA를 쓸 이유가 없는데 어떡함?
그래서 책에 없는 예제도 만들어봤음.
4. Immutable Object In Jpa Entity
Jpa Entity 자체를 불변으로 만들어서 사용할 수는 없다.
다만, 특정 속성(값)을 객체로 만들어 Embedded 클래스로 사용하면 특정 속성을 불변으로 만들어 사용하는 것은 가능하다.
아래는 일반적인 JPA Entity의 형태.

여기에서 email을 별도의 Email 객체로 분리하면 속성을 불변으로 사용할 수 있다.

이제 매번 값을 검증하지 않아도 된다.
5. multiple named constructor
책에서는 다양한 명명 생성자가 필요한 경우 private constructor를 만들어 공유하게 하면 된다고 하는데..
코틀린은 그냥 Init 블럭 사용하는 게 더 편함 ㅅㄱ

6. DTO는 private 접근 제어자를 사용하지 않는다.
7. DTO의 생성자는 예외를 배열에 수집해서 한 번에 반환하는 것이 좋다. (잘못된 인자들을 한 번에 알려주기)
8. mutable object에는 식별자가 필요하다.
9. immutable object에는 식별자가 필요 없다.
10. smart object
객체는 가능한 똑똑하게 설계하는 것이 좋다.
클라이언트가 일일히 외부에서 무언가를 계산하고 내부 구현을 알 필요가 없도록 하는 것이 좋다는 말이다.
이번 예제는 책에서 그대로 가져왔다.

위 객체는 x, y축을 자유롭게 이동 가능한 movePosition() 메서드와 x축, y축으로만 이동 가능한 moveX(), moveY() 메서드를 가지고 있다.
가령, 사용자가 Position 객체를 왼쪽으로 이동시키고 싶다면 moveX()의 인자에 음수를 주어야 할 것이고, 이는 클라이언트가 상세 구현을 알아야만 하도록 강제한다.

반면, 위와 같이 moveRight(), moveLeft(), moveUp(), moveDown()으로 메서드를 만들어 준다면 클라이언트는 별다른 고민 없이 메서드를 사용할 수 있다.
11. clone 메서드보다 유효성 검사가 가능한 생성자를 활용해라. (Java의 clone() 메서드가 어떻게 동작하는지는 이제 잊어버려서 모르겠다. 근데 그냥 쓰지 마라. (https://7357.tistory.com/281)
12. mutable 객체에는 메서드 체이닝을 허용하지 마라.
13. 메서드 기본 템플릿
(1) 사전 조건 확인
(2) 실패 시나리오 (예외처리)
(3) 행복한 경로 (본 시나리오)
(4) 사후 조건 확인 (단순 안전 점검용으로 일반적으로 필요하지는 않으나 레거시 코드 보수시 필요할 수 있음.)
(5) 반환하지 않거나, 결과값을 반환
14. 가변 객체의 명령 메서드는 반드시 반환값이 void여야 한다.
15. 되도록 값을 직접적으로 노출하지 말고 대안을 찾는다.
하지만 아쉽게도 JPA Entity의 경우 한계가 있을 수밖에 없긴 하다.
그래도 최대한 직접적으로 노출하지 않는 노력이 필요하다.

16. 접근자(Java Bean 규약에 따르면 Getter)는 명령 메서드가 아니라 단지 정보를 제공하는 것이므로 "get"을 붙일 이유가 없다.
17. 시스템 경계를 넘는 질의에는 추상화를 정의할 것(Clock, Repository, Kafka, RabbitMQ..)
18. 외부 라이브러리 변경에 영향을 받지 않은 서비스 구조를 만들기 위해서는 외부에 대한 요청을 추상화해야 한다.
시스템 경계를 넘어서는 부분에 있는 모든 것들에 해당되는 말이다.
가령 MailSender, RabbitMq, Kafka, Database, HttpClient 등..
영원한 것은 없다.
Spring 5.0 이전까지는 RestTemplate으로 Http 요청을 보냈지만, 현재는 WebClient가 대세가 되었다.
RabbitMq, Kafka 같은 Message Queue 또한 언제든 다른 메세지 큐 프레임워크를 사용하게 될 수 있다.
따라서 스프링에서 이를 편하게 사용할 수 있게 해주는 라이버리를 제공해준다고 하더라도 한 번 더 추상화를 통해 감싸고, infrastructure layer의 변경 여파가 service layer나 domain layer까지 전파되지 않도록 해야한다.
아래는 Naver Shopping Api(가상의) 호출을 위한 WebClient를 사용하는 직접적인 구현은 Infrastructure layer로 분리하고, 추상화된 NaverShoppingHttpClient만 Service Layer에 배치함으로써 외부 라이브러리에 대한 의존성을 분리하고 테스트 용이성까지 챙길 수 있는 사례이다.

19. 메서드가 너무 커지거나, 별도로 테스트해야 하거나, 시스템 경계를 지날 경우 별도 테스트를 생성한다.
20. 목 라이브러리를 사용하지 않는다.
(1) 좋은 디자인을 방해한다
(2) 코드를 읽고 유지하기 어렵다
21. 질의 메서드(getter) 뒤에는 숨겨진 명령 메서드 호출이 없어야 한다.
22. 질의 메서드를 테스트할 때는 실제 호출을 테스트하지 말고 직접 작성한 Mock과 Stub으로 대체한다.
23. 명령 메서드 유효 범위를 제한하고 이벤트를 사용해 부차적인 작업을 수행한다.
(1) 주 작업 외에 부수적인 작업을 저리하는 것을 나타내기 위해 이름에 And가 들어가야 하는가?
(2) 모든 코드 내용이 주 작업에 기여하는가?
아래의 코드는 (1), (2)를 위반하는 예시이다.

메서드 명칭은 changeUserPassword지만 실제로는 메일을 발송하는 역할까지 가지고 있다.
따라서 changeUserPasswordAndSendNotificationMail같은 메서드로 명칭을 바꾸는 방법도 생각해볼 수 있겠지만, 애초에 메일을 전송하는 것은 해당 메서드를 사용하는 클라이언트의 주요 관심사가 아니다.
또한, 필요에 따라 메일 전송은 백그라운드(비동기)로 처리해도 될 것으로 보인다.
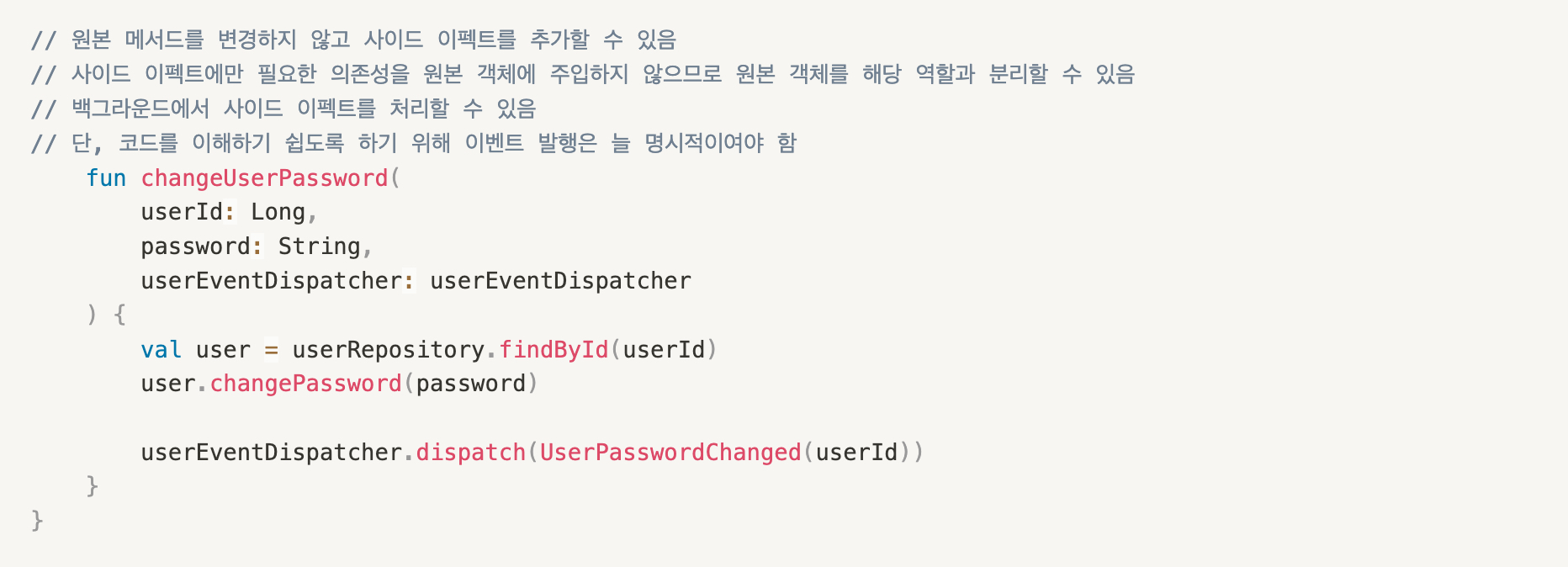
따라서 위와 같이 직접적으로 메일을 보낸다는 행동을 하기보다는, 유저의 메일이 변경되었다는 도메인 이벤트를 발생시키고 메일 전송의 책임은 다른 서비스에 위임함으로써 역할을 분리할 수 있다.
단, 주석에 적혀있듯이 이런 이벤트 발행은 코드를 이해하기 어렵게 만들 수 있기 때문에 늘 명시적이여야 한다.
24. Service의 상태는 영원히 불변이여야 한다.
25. 명령 메서드가 부수적인 명령 메서드를 실행할 경우, 테스트 시 해당 메서드는 목으로 처리한다.
(1) 위 예시의 EventDispatcher 또한 바로 사용하지 않고 한 단계 추상화하여 Mocking할 수 있을 것이다.
26. 일긱 모델과 쓰기 모델을 분리한다.
(1) 서로 다른 클라이언트는 Entity를 서로 다른 방법으로 사용한다. 가령, 어떤 클라이언트는 해당 객체의 명령 메서드를 사용해 개체의 데이터를 조작하려는 반면, 다른 클라이언트는 질의 메서드를 사용해 정보를 가져오기만 할 수 있다. 그럼에도 클라이언트는 동일한 객체를 공유하며, 심지어 그 모든 메서드를 필요로 하지 않거나 그 모든 메서드에 접근하지 않아야할 때도 모든 메서드에 접근한다.
(2) 개체를 변경할 권한이 없는 클라이언트에 변경할 수 있는 개체를 저달해서는 안된다.
(3) 지금 당장은 클라이언트가 변경하지 않더라도 어느 날 변경할 수 있으며, 그러면 어떤 일이 일어났는지 파악하기 어렵다.
(4) 읽기 모델이 별도 처리를 거치지 않아도 될 경우 굳이 서비스를 통과할 필요는 없다. (Controller에서 ReadOnlyRepository를 사용할 수 있음)
27. 매번 데이터를 직접 질의하는 것보다, 새로 추가된 데이터를 기록하고 기존에 저장된 데이터만 불러오는 방식으로 개선할 수 있다.
아래는 일반적인 데이터 저장, 불러오기를 처리하는 로직이다.
해당 방식은 데이터베이스 테이블에 많은 데이터가 적재될수록 성능에 영향을 미칠 수 있다.

매번 데이터를 읽어오는 대신, 데이터가 저장되는 시점마다 이벤트를 발행하여 캐시에 기록하는 방식으로 처리할 수 있을 것이다.
근데 그냥 캐시 정도는 이벤트 없이 저장해도 되지 않나..? ㅎ

28. 클래스 코드 자체를 변경하는 것보다, 객체 그래프 구조를 변경할 수 있게 해라.
-> 클래스 메서드 재정의는 다양한 문제를 유발할 수 있다.
29. 생성자 인자를 이용해 행위를 교체할 수 있게 해라.
30. 기존 코드의 기능을 확장하기 위해 상속을 사용하지 말아라.
-> 하위 클래스와 부모 클래스가 묶여서 부모 클래스의 변경으로 인해 하위 클래스의 동작이 망가질 수 있다.
31. 부득이하게 기존 코드의 기능을 확장해야할 때는 Decorator Pattern을 사용해라.
기존 엄청나게 복잡한 레거시 코드가 존재할 때, 사이드 이펙트를 추가해야 한다면 기존 코드를 건드리는 것보다 이를 감싸는 메서드를 만드는 것이 안전하다는 뜻이다.

위 사례는 기존 userService의 (엄청나게 복잡하다고 가정하자) changeUserPassword라는 메서드를 호출한 뒤 추가적으로 lastPasswordChangedAt에 새로운 값을 할당해주는 로직이다.
32. 클래스는 기본적으로 final 키워드를 사용해 상속을 막아라.
(1) 상속보다는 Composite Pattern을 사용해라
(2) 클래스를 확장하지 않으며, 메서드를 재정의하지 않을 것임을 클라이언트에게 명확하게 한다.
(3) 사용자가 행위를 변경하기 위한 더 나은 방법을 찾게 강제한다.
33. Controller
(1) 서비스에 대한 그래프 진입점 중 하나이다.
(2) Serivce나 Readonly Repository를 호출한다.
34. Service -> 님들 아는 그대로임
35. Write Repository
(1) Entity를 가져오고, Entity에 가한 변경을 저장하는 역할
(2) 추상화를 통해 getById(), save(), add(), update() 같은 범용 메서드만 노출한다.
36. Entity
(1) 응용 프로그램을 재시작해도 기억해야하는 것
(2) 개체는 응용 프로그램의 도메인 개념을 나타낸다
(3) 데이터와 연관된 유용한 method들을 제공한다.
(4) 흔히 named constructor를 가직 ㅗ있다.
(5) 수정자 (setter) 메서드를 가지고 있다.
(6) 식별자, 생명주기, 영속성을 가지고 있다.
37. VO
(1) primitive type 값들을 감싸고, 그 값에 의미나 유용한 method들을 더한다.
(2) immutable object
(3) 도메인별 용어를 사용해 의미를 추가한다. (ex -> val year: Int)
(4) 값의 유효성을 확인하여 생성 시 제한을 가한다.
38. Event Listener
(1) 의존성을 주입한 변경 불가능한 서비스
(2) 도메인 이벤트인 단일 인자를 받아들이는 메서드가 적어도 한 개 이상 존재
39. DTO
(1) 질의 메서드만 있는 질의 객체
(2) Immutable
(3) 특정 사용 사례를 위해 고안됨
(4) 객체를 가져오는 순간 필요한 모든 데이터를 사용할 수 있음
40. ReadOnly Repository
(1) 특정 사용 사례에 부합하는 질의 메서드가 있으며, 그 사용 사례에 한정적인 읽기 모델(DTO)를 반환한다.
41. 추상화
(1) Controller는 추상화가 필요 없다. 특정 프레임워크와 결합하며 특정 전달 메커니즘에 맞게 구현되었다. 컨트롤러는 인터페이스가 없거나 필요 없으며, 대체 구현은 프레임워크를 완전히 전환할 때만 제공하면 된다.
(2) Service는 추상화가 필요 없다. 사용하는 응용 프로그램의 매우 특정한 사용 사례를 나타내며, 요구사항이 바뀌면 응용프로그램 서비스 자체가 바뀌므로 인터페이스를 지니지 않는다.
(3) Entity와 VO는 추상화가 필요 없다. 이는 개발자가 도메인을 이해하는 특정환 결과물이며, 객체의 타입은 시간에 따라 내내 진화하며 인터페이스를 제공하지 않는다. 절대 인터페이스를 통하지 않고 있는 그대로 정의하고 사용한다.
(4) Repository는 추상화와 최소 한 개 이상의 구현체로 존재한다. Repository는 DB, File System, 외부 API 같이 으용프로그램 외부에 있는 것에 접초갛고 연결하는 서비스다. 마찬가지로 외부에 있는 서비스와 접촉하는 서비스도 일종의 Repoitory이므로 별도의 추상화가 필요하다.
42. 계층
(1) Infrastructure layer
- 외부 세계와 통신을 용이하게 하는 코드들이 존재한다
- service layer와 domain layer를 감싸고 있다.
- Controller
- Repository 구현체
(2) Service Layer
- Service
- Write Repository
- DTO
- Event Listener
(3) Domain Layer
- Entity
- VO
- ReadOnly Repository
43. 추상화
- Repository를 구현하지 않고 응용프로그램 서비스를 테스트할 수 있다.
- 기반 프레임워크, 데이터베이스 전환에도 쉽게 전환할 수 있다.
44. 이러한 객체 디자인 기본 규칙을 따르지 않았을 때 경고를 내는 정적 분석 도구를 만들 수 있다.
- 단, 규칙을 따르는 것이 중요하나 품질이 중요하지 않은 예외적인 상황에는 유연하게 임한다.
(1) 그런 코드는 오랜 시간 유지보수할 가치가 없다.
(2) 때로는 공들인 만큼 보상이 따르지 않을 수 있다.
(3) 단, 섣불리 판단하지는 말 것. 실세계 시나리오 중 95%에는 지름길이 없다.
45. Class Test VS Object Test
(1) Class Test
- 클래스의 한 메서드에 대한 의존성을 모두 Mock으로 바꾸고 테스트
- 구현 내용과 밀접해짐
- 클래스 자체가 바뀔 때마다 항상 바뀐다
- Like White box test
(2) Object Test
- Like Black box test
- 시스템 경계를 지나 도달하는 객체에 대해서만 Mock을 사용(Clock, Repository, Kafka ..)
- 단일 클래스 뿐 아니라 더 큰 코드 단위가 전체적으로 잘 동작하는 것을 확인
- 장기적으로 더 유용하다
46. 하향식 기능 개발
- Repository, Database Table, Entity 등의 추후 필요한 부품을 먼저 만들지 마라
- 부품을 서로 연결하기 시작하면 몇 가지 초기의 잘못된 가정으로 다시 만들어야하는 부분들이 보이고, 결국 조화롭게 연동되지 않는다는 것을 알게되면 그동안 개발에 쏟은 시간이 낭비된다.
- 사용자 시나리오를 먼저 정의하고, 상호작용의 개요를 먼저 작성한다.
- 개발을 완료했 을 때 해당 프로그램이 어떻게 동작하기를 기대하는지 고수준에서 명시하고, 이후 저수준 상세 내용을 개발해도 늦지 않다. (상세 내용은 블랙박스 취급)
- 완전한 기능을 기술하는 고수준 테스트 작성 → 단위의 저수준 테스트 작성 → 고수준 테스트는 모든 저수준 테스트가 성공해야 성공할 수 있음.
'Language & Framework > Java' 카테고리의 다른 글
| Kotlin Scope Function 복습 (3) | 2023.08.15 |
|---|---|
| 이펙티브 자바 (9) Cloneable 재정의는 주의해서 진행하라 (0) | 2023.01.20 |
| 이펙티브 자바 (8) equals를 재정의하려면 규약을 지켜라, equals 재정의 시 hashCode도 재정의하라. (0) | 2023.01.13 |
| 이펙티브 자바 (7) item8,9 : try-with-resources를 사용하라, finalizer, cleaner를 사용하지 말아라. (0) | 2022.12.31 |
| 이펙티브 자바 (6) 다 쓴 객체 참조를 해제하라 (0) | 2022.12.22 |



