
ArrayList와 LinkedList, 그리고 Vector은 List interface를 구현한 클래스이다.
이 중 Vector은 혼자 뒤에 List가 없는데. Collections framework(+List Interface)가 생기기 전에 만들어진 클래스라 그렇다.
ArrayList와 거의 같은 구현 원리와 기능을 가지고 있으며, ArrayList는 쓰레드와 비동기적으로 작동한다던지.. 배열이 추가 복사될 때 2배가 아닌 1.5배 늘어난다던지, 지원하는 세부 메서드가 다르다던지 등등의 차이점은 있으나 결론만 말하자면 이제와서 굳이 Vector을 사용할 이유는 없다.
우선 List, ArrayList, LinkedList의 특징을 간략하게 알아보자.
1. List
: List 인터페이스는 중복을 허용하며 저장순서가 유지되는 컬렉션을 구현하는데 사용된다.
2. ArrayList
: 데이터를 순차적으로 저장하며 공간이 부족하면 저장된 내용을 더 큰 배열에 복사해서 저장한다.
3. LinkedList
: 불연속적인 데이터를 노드로 연결하며 각 노드들은 자신의 다음 노드에 대한 참조(주소)와 데이터 값으로 구성되어 있다.
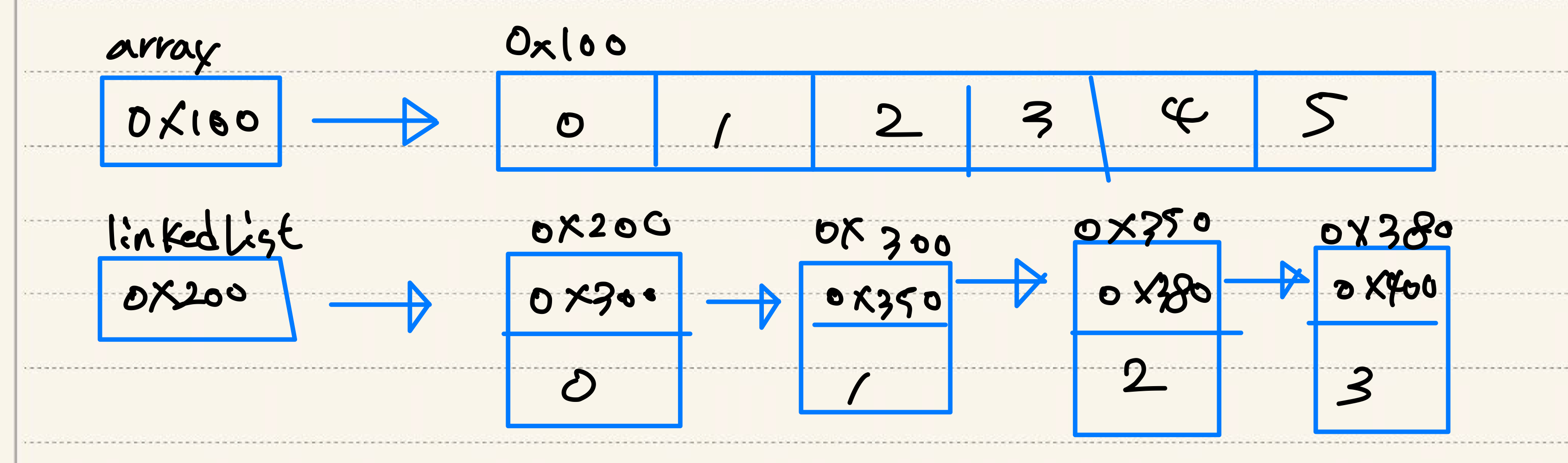
ArrayList와 LinkedList의 차이는 그림으로 표현하자면 위와 같다.
(사실 ArrayList와 LinkedList 모두 Object[] 배열이기 때문에 0,1,2,3,4,5같은 기본형 값이 아닌 객체에 대한 참조를 가지고 있다)
ArrayList의 생김새는 우리가 평소에 알고 있던 Array와 굉장히 비슷하고 친숙해 보이는데 심지어 스스로 배열이 확장되는 기능까지 가지고 있다니 정말 편리해 보인다.
LinkedList는 기본적인 Array의 단점들을 보완하기 위해 만들어진 자료구조이기 때문에 굉장히 낯선 형태를 가지고 있다.
그러면 우리가 평소에 어떤 자료구조를 사용해야 하는지, 성능은 어떤지 직접 확인해보자.
package CollectionFramework.LinkedList;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class LinkedList1 {
public static void main(String[] args) {
ArrayList<Integer> al = new ArrayList<>(2000000);
LinkedList<Integer> ll = new LinkedList<>();
System.out.println("====== 시작부터 추가");
System.out.println("ArrayList : " + add1(al)); // 26
System.out.println("LinkedList : " + add1(ll)); // 25
System.out.println("====== 중간부터 추가");
System.out.println("ArrayList : " + add2(al)); // 16716
System.out.println("LinkedList : " + add2(ll)); // 132
System.out.println("====== 중간부터 삭제");
System.out.println("ArrayList : " + remove2(al)); // 1710
System.out.println("LinkedList : " + remove2(ll)); // 147
System.out.println("====== 순차적으로 삭제");
System.out.println("ArrayList : " + remove1(al)); // 11
System.out.println("LinkedList : " + remove1(ll)); // 22
add1(al);
add1(ll);
System.out.println("====== 접근 속도");
System.out.println("ArrayList : " + access(al)); // 1
System.out.println("LinkedList : " + access(ll)); // 131
}
public static long add1(List<Integer> list) {
long start = System.currentTimeMillis();
for(int i=0; i<1000000; i++) {
list.add(i);
}
long end = System.currentTimeMillis();
return end - start;
}
public static long add2(List<Integer> list) {
long start = System.currentTimeMillis();
for(int i=0; i<100000; i++) {
list.add(500, i);
}
long end = System.currentTimeMillis();
return end - start;
}
public static long remove1(List<Integer> list) {
long start = System.currentTimeMillis();
for(int i=list.size()-1; i>=0; i--) {
list.remove(i);
}
long end = System.currentTimeMillis();
return end - start;
}
public static long remove2(List<Integer> list) {
long start = System.currentTimeMillis();
for(int i=0; i<10000; i++) {
list.remove(i);
}
long end = System.currentTimeMillis();
return end - start;
}
public static long access(List<Integer> list) {
long start = System.currentTimeMillis();
for(int i=0; i<10000; i++) {
list.get(i);
}
long end = System.currentTimeMillis();
return end - start;
}
}결과를 요약하면 다음과 같다.
1. 순차적으로 쓰기 => 비슷하다. (이론적으로는 ArrayList가 더 빠름.)
2. 순차적으로 지우기 => 비슷하다. (이론적으로는 ArrayList가 더 빠름.)
3. 중간부터 쓰기 => LinkedList가 빠르다.
4. 중간부터 지우기 => LinkedListr가 빠르다.
5. 중간에 있는 데이터 읽기 => ArrayList가 빠르다.
순차적 데이터 추가, 삭제의 경우 ArrayList와 LinkedList의 성능차가 크지 않지만 데이터를 중간부터 삭제하는 작업이나 데이터를 읽는 속도는 굉장한 차이가 나는 것을 확인할 수 있다.
왜 이런 결과가 나타났을까?
ArrayList의 경우 충분한 공간이 확보되어 있다면 순차적으로 추가 삭제시 null 값을 참조로 변경하거나 참조를 다시 null로 바꾸면 되는 간단한 작업이기 때문에 LinkedList보다 빠르다.
단, 중간부터 추가 혹은 삭제하는 경우 ArrayList는 빈 공간을 확보하거나 배열을 재배치해야 하기 때문에 LinkedList보다 느리다.
아래는 실제 ArrayList와 LinkedList의 remove 메서드 코드이다.
1.ArrayList remove
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}2. LinkedList remove
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
ArrayList의 remove 메서드를 살펴보면 배열 중간에 있는 값을 삭제할 때마다 배열 복사의 과정을 거치고 있는 것을 확인할 수 있다.
반면 LinkedList는 첫번째 값부터 매칭되는 값을 탐색한 뒤 해당 값에 대한 참조만 끊어내는 방법을 채택하고 있기 때문에 LinkedList가 더 유리할 수 밖에 없다.
그러나 오히려 단순 읽기 속도는 ArrayList가 더 빠른데 위에서 봤던 그림을 다시 보도록 하자.
ArrayList는 배열의 주소가 정해져있고, 그 안의 값들은 데이터 타입의 크기에 따라 주소가 정해진다.
예를 들자면 0x100에 위치한 배열에 있는 값들은 0x100 0x104 0x108 0x10C.. 이런 규칙성을 가진다는 것이다.
따라서 중간에 있는 값을 읽어올 때는 배열의 주소 + 데이터 타입 * 인덱스로 계산하면 한 번에 필요한 값을 찾아낼 수 있다.
그러나 LinkedList는 불연속적인 참조를 노드로 이어놓은 것이기 때문에 10번째 노드의 값을 읽기 위해서는 0번부터 9번까지 타고 올라가야하며, 100번째는 0번부터 99번까지, 1000번째는 0번부터 999번까지.. 모두 순차적으로 확인해야만 데이터에 접근 가능하기에 ArrayList보다 느릴 수 밖에 없는 것이다.
사실 이 성능 예제는 정말 극한의 상황에서의 테스트이고 실제 사용 시에는 이렇게까지 연속적으로 중간의 값만 읽거나 수정할 일은 없기 때문에 둘의 성능 격차가 그렇게 유의미할 정도로 심한 경우는 거의 없다고 한다. 그래도 극한의 성능 끌어올리기를 위해서는 미리 각 자료구조의 특징을 잘 파악하고 적재적소에 맞게 사용하는 것이 중요할 것이다.
'Language & Framework > Java' 카테고리의 다른 글
| 자바 예외 (2) java.io.InvalidClassException: InputAndOutput.Child; no valid constructor (0) | 2022.06.22 |
|---|---|
| 자바 예외 (1) java.io.NotSerializableException (0) | 2022.06.21 |
| 자바 Wrapper 클래스의 기본 활용 (0) | 2022.06.09 |
| 자바 Math 클래스의 기본 활용 (0) | 2022.06.09 |
| 자바 String에 대한 이해와 기본 메서드 총 정리 (0) | 2022.06.09 |



