1. 비트 그룹 (뭉탱이 ㅎ)의 명칭

비트 개수의 기본 단위는 혼돈의 시대를 거쳐 8비트(바이트)가 기본 단위로 사용되게 되었다.
다들 알다시피 현재 컴퓨터가 한 번에 처리할 수 있는 가장 큰 뭉탱이는 64비트(double word)이다.
이는 자바나 c, c++의 double의 크기와 같다. (그러면 당연히 word가 int와 크기가 같다는 사실을 알 수 있을 것이다.)
그런데 우리는 디스크나 메모리 등의 용량을 표현할 때, 킬로바이트라는 말을 많이 사용한다.
이것은 실제 1000이 아니라, 2진법으로 표현할 수 있는 1000에 가장 가까운 수인 1024를 뜻한다.
그러나 한 미국 변호사가 디스크 크기가 광고에 나온 것보다 작다며 제조사를 고소하여 두가지 표준이 자리잡게 되었는데, 바로 1kB를 1000bytes로 표기하는 SI standard와 1KiB를 1024bytes로 표기하는 IEC standard 표기법이다.
왜 1기가가 1000메가가 아니냐는 질문을 엄청나게 많이 볼 수 있는데, 이제 우리는 정답을 알고 있으니 유식하게 답변해주자.
다만 너무 아는 척하며 말하면 오히려 역효과니까 겸손하게 사실 전달만 하는 것이 좋다. 눈치 있게 살자.
https://wiki.ubuntu.com/UnitsPolicy
UnitsPolicy - Ubuntu Wiki
Rationale There are two ways to represent big numbers: You could either display them in multiples of 1000 = 10 3 (base 10) or 1024 = 2 10 (base 2). If you divide by 1000, you probably use the SI prefix names, if you divide by 1024, you probably use the IEC
wiki.ubuntu.com
2. ASCII
옛날 옛적에는 Character만으로 문자를 표현하기도 했으나, 시대가 지나며 새로운 문자 표현법이 절실해졌다.
여러 표현법 중에서 승리하고 끝까지 살아남아 1963년 세계 표준으로 자리 잡은 것이 (ASCII, American Standard Code for Information Interchange)이다.
(이 때 패배하고 역사의 뒤안길로 살아질 줄 알았으나 아직도 일부 영역에서 사용되고 있는 것이 IBM의 BCD 표현법이다.)

아스키코드는 7비트 부호체계이며, 7비트인 이유는 나머지 1개 비트를 통신 에러 검출용으로 비워놨기 때문이다.
재미있는 사실은 문자 뿐 아니라 제어 메세지도 ASCII에 포함되어 있다는 사실인데, 10진수 기준 6번과 22번을 보자.
Three-HandShake에 사용되는 Ack와 Syn이 여기에 있다.
혹시 three handshake가 무엇인지 모른다면 아래 글의 TCP/IP 통신을 읽어보자. 웹 개발자라면 반드시 알아야하는 것이다.
https://7357.tistory.com/122?category=1068159
네트워크 (1) 기본 이해 (IP, TCP, UDP, topology)
1. 우리가 사용하는 인터넷은 어떻게 연결되어 있는가? 보통 개발 공부를 하며 배우는 서버와 클라이언트의 관계는 "클라이언트에서 요청하면 서버에서 데이터를 준다"가 끝이지만 서버와 클라
7357.tistory.com
아무튼, 그렇게 완벽한 줄 알았던 ASCII 표준은 컴퓨터를 사용하는 국가가 늘어남에 따라 국제 표준화기구(ISO)에서 ISO-646, ISO-8859를 도입하여 ASCII를 확장해 각 국가에서 남는 공간에 문자를 밀어넣었다.
3. Unicode
비트를 아끼겠다고 1바이트에 꾸역꾸역 문자를 밀어넣은 결과, 결국 대혼란이 벌어지고 말았다.
다른 문자를 가진 국가끼리 데이터를 전송하니 모든 글자가 깨져버리는 참사가 벌어진 것이다.
결국 유니코드라는 새로운 표준 문자 전산 처리 방식이 생겨났고, UTF-8의 도입으로 세계는 드디어 멀쩡한 글로벌 통신을 할 수 있게 되었다.
유니코드는 문자 코드에 따라 각기 다른 인코딩을 사용하며 UTF-8 방식이 가장 널리 쓰인다.
UTF-8은 문자를 8비트 덩어리(Octet)의 시퀀스로 인코딩하며, 모든 아스키 문자는 위에서 배웠듯이 7비트 안에 들어가기 때문에 남아있는 MSB의 비트는 비트의 크기와 문자간의 경계를 찾는데 유용하게 쓰인다.
유니코드는 당초 1문자가 16비트였으나 Unicode 2.0에서는 21비트로 확장되었다.
(그러나 Java는 호환성을 위해 여전히 16비트까지만 지원하고 있다.)
유니코드는 보기에는 별 거 아닌 것 같지만, 이것만 적어내려가도 내가 평상시에 쓰는 글의 2배이기 때문에 더 이상의 설명은 생략한다.
궁금하면 아래 블로그에서 읽어보자, 아주 잘 정리되어 있다.
https://theoryof0.tistory.com/101
유니코드를 제대로 이해하는 방법
유니코드(Unicode)는 컴퓨터에서 체계적이고 통일된 방식으로 문자를 처리하기 위해 만든 국제 기술 표준입니다. 유니코드가 널리 사용되면서 관련 분야 종사자 이외의 일반 사용자들도 유니코드
theoryof0.tistory.com
4. 비트의 다양한 인코딩
(1) Quoted-Printable Encoding (QP 인코딩)
8비트 데이터를 7비트 데이터만 지원하는 통신 경로를 통해 송수신하기 위해 만들어진 인코디 방식으로써, 전자 우편의 첨부 처리를 위해 고안되었다.
이 방법은 ASCII 문자가 아닌 문자를 =과 16진수, 총 3자리로 표현하는데 결국 문자가 각각 한바이트로 늘어나는 것이다.
이는 영어권 국가에서는 별로 문제가 되지 않지만 한국과 같은 비영어권 국가에서는 모든 문자를 3바이트로 죄다 인코딩하게 된다.
ASCII문자가 많은 일반 텍스트나 HTML의 경우 QP방식으로 인코딩하지만, 한글이나 바이너리 파일 같은 경우는 주로 base64 인코딩을 사용한다.
자세하게 알고 싶으면 아래 링크를 확인해보자.
https://m.blog.naver.com/blow1/140015739676
인코딩 & 디코딩
1. 인코딩과 디코딩1) 전자메일 서비스는 초기에 RFC 822를 기반으로 정보교환이 이루어졌으며, 이 RF...
blog.naver.com
(2) base 64 인코딩
QP 인코딩의 비효율적인 부분을 보완한 방법으로, 8비트의 이진 데이터를 공통 ASCII 문자들로 이루어진 문자열로 바꾸는 인코딩 방법이다.
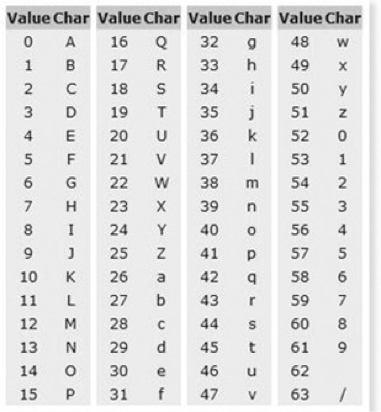
ASCII 코드는 7비트 인코딩인데 나머지 1비트가 국가별로 상이하게 처리되지만 base64는 공통 ASCII만 처리하기 때문에 바이너리 데이터를 안전하게 전송할 수 있다.
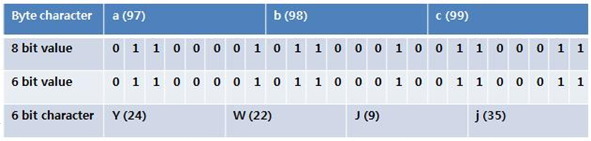
위 이미지에서 확인할 수 있듯이 base 64 인코딩은 8비트 표현법에 비해 33% 비효율적이지만 신뢰할 수 있는 데이터 전송을 위해 사용된다.
(3) URL 인코딩
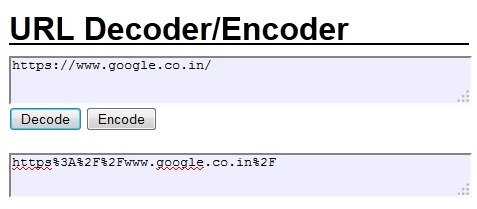
드디어 우리가 봤던 URL의 수많은 %들의 비밀이 풀리는 순간이다.
URL 인코딩은 URL에서 사용하면 의미가 왜곡될 수 있는 문자들을 '%xx'의 형태로 변환하는 것을 의미한다.
첫번째로 ASCII 문자가 아닌 경우 URL에 표기할 수 없으므로 %형식으로 변환되며, 이미 예약된 의미를 가지고 있는 문자의 경우에도 이스케이프 처리가 필요하다.
( 예시 : '/'는 URL에서 각 부분을 구별하는 특별한 의미를 가지는데 이 문자의 아스키코드는 10진수로 47, 16진수로는 2F이다. /를 URL에 사용하되 구분자의 의미로 사용하고 싶지 않은 경우 %2F라는 16진수 문자열로 대체한다)
(4) RGBA
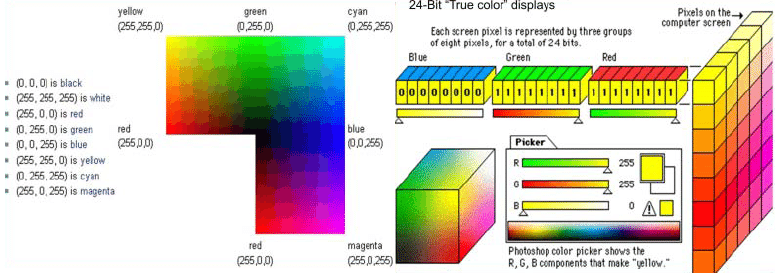
css에서 RGBA를 그렇게 많이 사용하면서도 Read Green Blue Alpha라는 것만 알았지 그 내면의 것은 궁금해하지 않았는데, 드디어 알게 되었다.
컴퓨터 디스플레이에 Picture Element(pixel)을 찍어서 컴퓨터 그래픽을 표현하게 되는데, 이 때 빨간색, 녹색, 파란색을 조합하여 색을 만들며 이것을 RGB색 모델이라고 부른다.
24비트를 사용해 1천만에 가장 가까운 2제곱수에 해당하는 색을 표현하며, 이 24비트는 8비트 세개로 나뉘어 각자 하나씩 색상을 담당한다.
그런데 우리가 이 글의 제일 위에서 봤던 비트 그룹을 생각해보자.
24비트 그룹이라는 것은 존재하지 않는다. 그래서 어쩔 수 없이 32비트(word)를 사용하게 되는데, 이 때 남는 부분을 그냥 버리는 것이 아니라 투명도를 나타내는 것에 사용한다.
1984년 루카스 필름의 톰 더프Tom duff와 토머스 포터Thomas Porter은 각 픽셀에 알파라는 투명도 값을 추가해 기존 색상과 투명도의 합성을 구현하는 공식을 구현했고, 이것은 표준으로 자리잡았다.
(알파채널은 직접 출력될 색상을 나타내는 것이 아니라 위에서 언급했듯이 그래픽 프로세서 등에서 합성 공식을 통해 계싼하는 것이므로 색상을 나타내는 것이 아니다.)
알파가 0이면 투명, 완전히 불투명하면 1이다.
예 1: RGBA (0,255,0,1)은 완전히 밝은 밝기의 불투명한 빨간색이다.
예 2: RGBA (0,127,0,0.5)는 중간 정도 밝기의 반투명한 빨간색이다.
참고로 RGB가 아니라 #형식의 색상 표기 방식도 많이 봤을텐데, 그것은 UTF-8방식으로 표현한 색 표기법이며 URL 인코딩과 비슷하게 16진 트리플렛으로 표현한다. (각각 8비트 값을 16진의 두자리 문자 표기로 바꿈.)
다만 이 방식은 투명도를 표현할 수 없다.
'CS ﹒ Algorithm > Computer architecture' 카테고리의 다른 글
| 컴퓨터 구조 (5) 클럭과 순차논리(래치/ 플리플롭/ 카운터) (0) | 2022.09.26 |
|---|---|
| 컴퓨터 구조 (5) 아날로그와 디지털/ 디지털 하드웨어의 역사/ 집적회로(IC)와 논리회로(Logic gate) (0) | 2022.09.19 |
| 컴퓨터구조 (3) 이진 실수 표현법(부동 소수점) / 8진법 / 16진법 / BCD / 구별법 (3) | 2022.08.22 |
| 컴퓨터 구조 (2) 2진수의 더하기 연산/ 논리 연산/ 음수 표현 (0) | 2022.08.19 |
| 컴퓨터 구조 (1) 비트 / 불대수, 드모르간의 법칙 / 2진법 개념 (0) | 2022.08.16 |



