
중앙 처리 장치 (Centrall Processing Unit, CPU)
:기본적으로 기억, 해석, 연산, 제어의 역할을 하고 있으며 컴퓨터에서 이외의 다른 요소들은 모두 CPU를 지원하는 역할이다.
1. 산술 논리 장치
중앙 처리 장치의 핵심 부품은 산술 논리 장치(Arithmetic logic unit, ALU)이며, ALU는 산술 계산, 불리언 대수 및 여러 산술 연산을 수행하는 역할을 한다. ( CPU, GPU를 비롯한 여러 유형의 컴퓨팅 회로의 기본 빌딩 블럭이다. )

1. Integer Operand(정수 피연산자) : 피연산자 표현하는 비트가 입력된다.
2. Opcode(연산 코드) : 피연산자에 적용할 연산자(operator)를 결정한다.
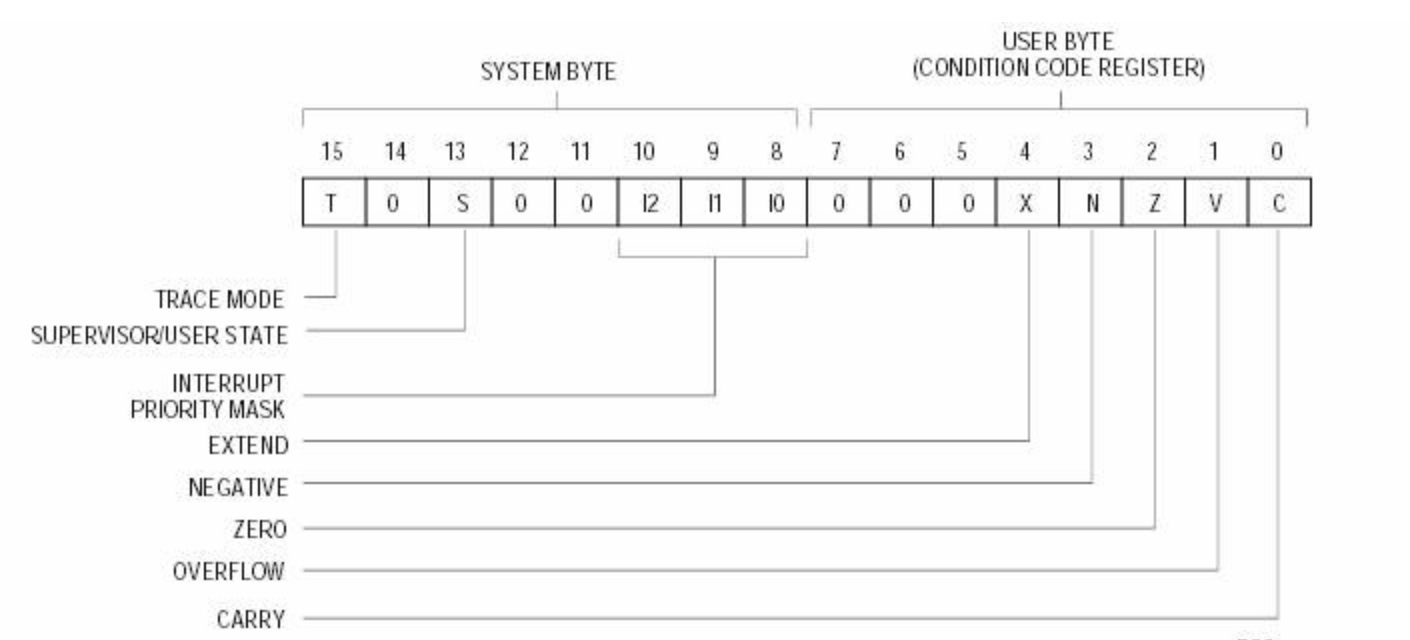
3. Status(상태 코드, 조건 코드) : Overflow, Underflow, 모든 비트의 논리값이 0, 산술 결과 음수여부 등 작업 결과에 대한 추가 정보를 전달한다.
4. Integer Result : 설명이 필요 없을 것이다.
Status Code는 Condition Code Register에 저장된다.

2. 시프트
시프트 레지스터(shift register)는 데이터 저장/이동, 직렬/병렬화 등에 사용한다.
여러개의 프리플롭을 배치하여 왼쪽 시프트는 어떤 숫자의 모든 비트를 왼쪽으로 1비트씩 옮기고, MSB를 버리고 가장 오른쪽 비트에 0을 추가하며, 오른쪽 시프트는 어떤 숫자의 모든 비트를 오른쪽으로 0비트씩 옮기고, LSB를 버리고 왼쪽 비트에 0을 추가한다.
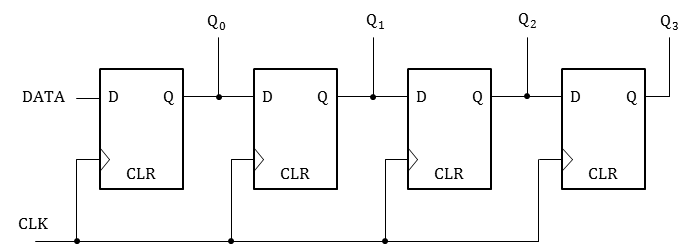
위는 가작 기본적인 형태의 순차적 시프트 레지스터이며 직렬 연결을 병렬 출력해주고 있기 때문에 Serial-in parallel-out이다.
(물론 반대로 병렬 연결을 직렬로 출력해주는 시프터도 존재한다.)
그러나 이는 1비트를 시프트할 때마다 한 클록이 필요하기 때문에 속도가 느리다. 이 때문에 초기 컴퓨터에서는 데이터 처리를 위해 메모리에 주요 부품으로 사용됐으나 현재의 컴퓨터 메모리에는 사용되지 않는다.

Mux(실렉터)와 조합 논리를 사용한 배럴 시프터(Barrel shifter)로 이 문제를 해결할 수 있다.
시프트 뿐 아니라 2진 연산 등의 역할을 수행할 수 있다.
배럴 시프터는 ALU와 함께 마이크로프로세서의 중요한 구성 요소역할을 하며 부동소수점 연산에 있어서도 핵심 부품이다.
(예를 들면 가산기와 배럴 시프터를 조합해 조합 논리 곱셈기를 만들 수 있다.)
3. 제어 장치
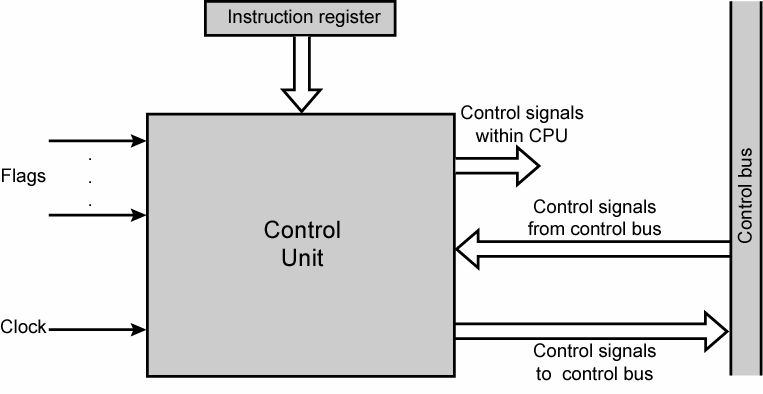
지금까지 소개한 것들은 모두 연산을 수행해 출력하는 역할을 수행할 뿐 입력 신호를 보내주는 제어장치(Control unit)가 필요하다.
제어장치는 외부 명령을 받아 명령어를 해독하고, 이를 이용해 일련의 제어 신호를 생성하여 CPU에 접속된 장치들에 대한 데이터 이동 순서 조정 및 CPU내 데이터 흐름 제어, 명령어 인출 해독 실행 등을 순서에 맞춰서 처리한다.
제어 장치는 기억장치 버퍼 레지스터, 기억장치 주소 레지스터, 명령 레지스터, 명령 해독기, 프로그램 카운터로 구성되어 있다.
프로그램 카운터를 통해 다음 명령어를 결정하고, 주 기억장치에서 명령을 인출하여 기억장치 버퍼 레지스터와 명령 레지스터에 임시 저장한 뒤 명령 해독기에서 명령어를 해독한다.
명령어 해독 과정이 끝나면 해독된 내용을 연산장치로 전달하고 이를 반복한다.
참고로 이런 식으로 실행되는 컴퓨터를 프로그램 저장 방식 컴퓨터(stored-proream computer)라고 부르며 이는 앨런 튜링의 튜링 머신으로부터 비롯되었다.
https://ko.wikipedia.org/wiki/%ED%8A%9C%EB%A7%81_%EA%B8%B0%EA%B3%84
튜링 기계 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 인공지능의 정도를 판별하는 테스트에 대해서는 튜링 테스트 문서를 참고하십시오. 튜링 기계의 작동 방식을 묘사하는 그림임 수학 또는 이론 전산학에서 튜
ko.wikipedia.org
그리고 이것을 최초로 전자식 컴퓨터에 도입한 것은 존 폰 노이만이며, 폰 노이만 구조는 아직까지 이어져오고 있다.
폰 노이만 구조 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 폰 노이만 구조(영어: Von Neumann architecture)는 에드박의 보고서 최초 초안(First Draft of a Report on the EDVAC)에서 수학자이자 물리학자 존 폰 노이만과 다른 사람들이
ko.wikipedia.org
4. 명령어 집합

명령어 집합 구조(Instruction Set Architecture, ISA)는 마이크로프로세서가 인식해서 기능을 이해하고 실행할 수 있는 기계어 명령어를 이야기하며, 명령어는 보통 Opcode(명령어의 종류)와 Operand(피연산자)로 구성되어 있다.
명령어의 종류에 따라 Operand가 없을 수도, 여러개일 수도 있다.
4-1. 주소 지정 방식
(1)즉시 주소 지정
: 명령어 자체에 피연산자 데이터가 포함되어 명령어가 인출될 때 피연산자도 자동으로 인출하는 방법으로 작은 값의 정수를 지정할 때 사용한다.
피연산자 인출을 위한 메모리 참조가 필요 없기 때문에 속도는 가장 빠르지만 상수만 가능하고 상수 값의 크기가 필드 크기로 제한된다.
ex> 상수 값과의 연산
(2)직접 주소 지정
: 메모리에 위치한 피연산자의 주소를 지정한다.
컴파일할 때 알려진 주소의 전역 변수에 접근할 때만 사용 가능하다. (값은 변할 수 있으나 주소는 변화 불가)
ex> 전역 변수 접근
(3)간접 주소 지정
: 메모리 참조가 두 번 이상 일어나는 경우 사용한다.
데이터를 가져오는 시간이 오래 걸리며 프로그램 수행 시간이 길어진다.(현재 거의 사용되지 않는 방식)
ex> 지역 변수 접근
(4) 레지스터 주소 지정
: 메모리가 아닌 레지스터에 저장될 뿐 즉시 주소 지정과 같은 방식으로 작동한다. 가장 일반적인 방식이다.
ex> 연산 중간 결과의 저장
(5) 레지스터 간접 주소 지정
: 직접 주소를 명령어에 포함하지 않고, 포인터를 통해 메모리 주소를 레지스터에 저장한다.
전체 메모리 주소가 없어도 참조가 가능하다.
ex> 포인터 접근
(6) 번위 주소 지정
: 특정 레지스터에 저장된 주소에 변위(인덱스)를 더해 실제 피연산자가 저장된 메모리 위치를 지정한다.
ex> 배열 접근
4-2. 분기 명령어

컴퓨터가 다른 명령 시퀀스의 실행을 시작하도록 지시함으로써 명령의 기본 실행 지시 순서에서 벗어날 수 있게 하는 역할을 한다.
분기(branch) 명령은 주로 프로그램 루프와 조건문의 제어 흐름을 구현하기 위해 사용된다.

이제 명령어의 구성인 분기 명령어(branch), 명령 코드(opcode), 주소 지정 방식이 모두 모였기 때문에 위와 같이 분기가 있는 절차적인 프로그래밍이 가능하다.
+ 명령어 레지스터가 따로 존재하여 명령어를 가져와서 임시로 보관하고 처리하는 과정을 반복한다.
4-3. 데이터의 흐름 제어
(1) Hardwired 방식
페치와 실행에 여러 단계가 필요하기 때문에 카운터가 각 단계를 체크하며, 카운터, 명령코드, 분기코드가 제어 신호를 결정한다.
가장 복잡한 연산의 경우 3단계까지 필요하기 때문에 카운터는 2비트 카운터여야 한다.
(1비트는 2까지만 셀 수 있다는 것을 상기하자.)
그리고 데이터의 흐름 제어를 모두 논리 회로 설계에 맡긴다면..

이런 무시무시한 녀석이 탄생한다. 물론, 우리는 이것이 굉장히 간소화된 그림이라는 사실을 알아야 한다.
당연히 이 녀석은 속도만큼은 제일 빠르다. 그러나 만들기 힘들고, 비용도 많이 들 뿐더러, 수정은 힘들다고 생각해야 한다.
그래서 우리는 대안으로 마이크로 코드를 선택할 수 있다.
(2) Micro code 방식

마이크로 연산을 수행하기 위해 필요한 제어 신호(비트들의 모임이다.)을 제어 워드라고 부른다.
이러한 제어 워드가 제어 메모리(기억 장치)에 저장될 때 이를 마이크로 프로그램이라고 하고, 이러한 방식의 제어장치를 마이크로 프로그램된 제어장치라고 한다.
쉽게 말하자면 CPU를 만들기 위해 CPU 기술자가 내부 메모리에 프로그래밍을 한 것이다.
경이롭지 않은가? 우리가 만드는 컴퓨터를 만들기 위해 저 작은 부품 안에도 프로그래밍된 부품이 들어있는 것이다.
(그야말로 마이크로 프로그램이라는 명칭이 알맞다고 할 수 있다.)
(3) RISC와 CISC
위에서 이어지는 내용이라고 봐도 무방하다.
1. CISC (Complex Instruction Set Computer)CISC는 현재 우리가 알고 있는 대부분의 CPU를 설계한 방식으로써 위에서 언급한 마이크로코드 방식을 기반으로 작동한다.이름부터 복잡 명령어 집합 컴퓨터로써 무수히 많은 명령어가 존재하며, 명령어 해석에 필요한 회로도 복잡하고 병렬 처리(파이프 라인)도 쉽지 않다. (따라서 디코더가 비대해진다는 심각한 단점이 존재한다.)트랜지스터 집적에 있어서도 효율성이 떨어진다.명령어의 길이를 최대한 줄여서 최소 메모리를 사용하도록 만들어 효율을 높였으나 현재에 와서는 메모리 비용이 저렴해지며 장점이 퇴색되게 되었다.
다만 하위 호환성만큼은 아직도 RISC보다 앞서는 장점으로 꼽히고 있다. RISC는 CPU 구조가 바뀌어 처리 비트 단위가 생기면 문제가 생길 수 밖에 없기 때문이다.
2. RISC (Reduced Instruction Set Computer)
RISC는 여러 프로그램을 분석한 결과 CISC에서 쓰이는 수많은 명령어 중 대다수가 거의 사용되지 않는다는 것을 알게되어, 명령어셋과 마이크로 아키텍처 설계에 대해 새로 제시한 개념이다.
명령어를 크게 줄여 디코더가 단순화되고 따라서 하드웨어 구조가 단순해졌으며 남는 트랜지스터는 다른 목적으로 할당하여 성능이 향상되었다.
레지스터 개수를 늘려 메모리에 의존도를 낮췄고, 명령어 시퀀스 경우의 수가 줄어 어셈블러 및 컴파일러 설계가 훨씬 단순해졌다. 맥북의 M1칩셋이 RISC에 속한다.
다만 이는 모두 이론적인 부분에서 작성된 내용일 뿐, 실제로는 CISC와 RISC가 서로의 장점을 많이 베끼면서 그 경계가 굉장히 애매해졌다.
이미 수많은 ARM 칩셋들이 출시되었다가 소리소문 없이 사라진 것을 생각했을 때 애플사의 ARM칩셋이 성공한 것은 RISC 기반이라서 그렇다고 할 수는 없을 것이다. (그러나 여전히 병렬처리 만큼은 RISC가 압도적으로 유리한 것이 사실이다.)
'CS ﹒ Algorithm > Computer architecture' 카테고리의 다른 글
| 컴퓨터 구조 (8) CPU 형태/ 운영체제 기반 지식(메모리, 프로세스 관리) (0) | 2022.10.06 |
|---|---|
| 컴퓨터 구조 (6) 메모리의 종류와 오류 검출 (Register, RAM, ROM, HDD, Flash) (0) | 2022.09.28 |
| 컴퓨터 구조 (5) 클럭과 순차논리(래치/ 플리플롭/ 카운터) (0) | 2022.09.26 |
| 컴퓨터 구조 (5) 아날로그와 디지털/ 디지털 하드웨어의 역사/ 집적회로(IC)와 논리회로(Logic gate) (0) | 2022.09.19 |
| 컴퓨터 구조 (4) 비트 그룹의 명칭과 다양한 비트 표현(ASCII/ Unicode/ URL/ RGB .. etc) (0) | 2022.08.28 |



